
Contact : Bertrand Coüasnon ( Bertrand.Couasnon@irisa.fr )
DocRead est un générateur automatique de systèmes de reconnaissance de documents structurés, développé grâce à la méthode DMOS. Il est constitué d’un compilateur du langage EPF (permettant de décrire un document à l’aide d’une grammaire), d’un module d’analyse lié à ce langage, d’un module de vision précoce (binarisation et extraction de segments) et d’un classifieur ayant des capacités de rejet.
Ce générateur nous permet une adaptation rapide à un nouveau type de document. En effet, il faut simplement définir une nouvelle grammaire (à l’aide d’EPF) qui décrit le nouveau type de document et, si nécessaire, il faut effectuer un nouvel apprentissage du classifieur pour lui permettre de reconnaître de nouveaux symboles. Le système de reconnaissance adapté est alors automatiquement produit par compilation.
Grâce à ce générateur, nous avons défini un certain nombre de systèmes de reconnaissance :
- ScoRead : prototype de reconnaissance de partitions musicales ;
- MathRead : prototype de reconnaissance de formules mathématiques ;
- TennisRead : prototype de reconnaissance de terrain de tennis dans des vidéo ;
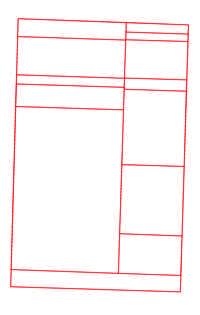
- TabRead : prototype de reconnaissance de structures tabulaires ;
- NatuRead : prototype de reconnaissance de décrets de naturalisation du XIXe siècle. Ce sont des formulaires uniquement manuscrits ;
- FormuRead : logiciel qui permet d’extraire automatiquement la structure de formulaires d’incorporation militaire du XIXe siècle, malgré leur dégradation. Ce logiciel a été testé sur 60 223 pages des Archives de la Mayenne et a montré ses très bonnes capacités.
|

|
|